
앞서, CPU를 virtualize하기 위해서는 OS가 동시에 동작하는 것처럼 보이는 프로그램들에게 물리적인 CPU를 공유해야한다고 설명했다.
기본 아이디어는 한 프로세스를 잠시 실행했다, 다른 프로세스를 실행하고, 또 다른 프로세스를 돌아가며 실행하는 것이다.
이걸 CPU의 time sharing이라고 한다.
하지만 time sharing에는 몇가지 문제들이 있다.
1. Performance
과도한 오버헤드 없이 좋은 성능을 유지하며 time sharing을 할 수 있을 것인가.
2. Control
어떻게 cpu를 컨트롤하며 효율적으로 프로세스들을 실행할 수 있을 것인가.
Basic Technique : Limited Direct Execution
프로그램을 빠르게 실행하기 위해서 OS는 limited direct execution을 제공한다.
왜 "제한된" direct execution을 제공하는 것일까?
direct execution은 말 그대로 그냥 cpu에 바로 프로그램을 실행하는 것이다.

단순하고 좋지만 몇가지 문제가 있다.
1. 프로그램을 효율적으로 실행하면서 OS가 프로그램에게 원치 않는 동작들을 제한 할 수 있을 것인가.
2. 프로세스를 실행하고 있을 때, 어떻게 현재 실행중인 프로세스를 멈추고 다른 프로세스로 전환(time sharing) 할 수 있을 것인가.
결국 OS는 제한된 direct execution을 통해 이 문제를 해결할 수 있다.
자 그럼 이제 문제를 하나씩 해결해 보자.
문제점 1 : Restricted Operation
1. 프로그램을 효율적으로 실행하면서 OS가 프로그램에게 원치 않는 동작들을 제한 할 수 있을 것인가.
이 문제는 언제 발생할까?
만약 프로세스가 I/O요청 또는 또 다른 자원에 접근을 요청하는 등 restricted operation을 원한다면 어떻게 해야 할까?
이때 프로세스가 원하는 모든 작업을 허락하고 실행하는 것은 위험하다.
예을 들어, 파일에 접근하기 전에 권한을 체크하는 파일 시스템을 만들 때, 우리는 프로세스들이 파일에 I/O 작업을 하는 것을 막아야 한다.
이를 해결하기 위해서 새로운 프로세서 모드를 제공한다. 바로 user mode와 kernel mode이다.
kernel mode로 실행하는 코드는 I/O요청과 restircted instruction같은 previleged operation을 실행할 수 있다.
반면 user mode로 실행하는 코드는 할 수 있는 것이 제한되어 있다.
그럼 user mode로 코드를 실행할 때 previleged operation을 하고 싶으면 어떻게 해야할까?
→ system-call number를 통해 필요한 시스템 콜을 간접적으로 호출한다.
user mode에서 system call을 직접 실행하는 것이 아니다. user mode에서는 trap handler의 주소를 알지 못한다.
- 시스템 콜을 실행하기 위해서는 프로그램이 trap instruction을 실행해야 한다.
trap instruction은 커널로 jump하고 kernel mode로 변경한다.
- 반대로 돌아 오기 위해서는 return-from-trap instruction이 있다.
trap instruction을 호출했던 user프로그램으로 되돌아오고 user mode로 다시 변경한다.
(trap을 실행하고 return-from-trap으로 user프로그램을 돌아올 때 정확히 돌아오기 위해서는
프로세서가 trap instruction을 호출하는 프로세스의 program counter, 레지스터 등을 kernel stack에 잘 저장하고 있어야 한다.)
다른 중요한 논의 거리로는 trap instruction을 호출하는 프로세스가 jump할 주소를 명시하는 것도 아닌데 어떻게 OS내부의 어느 코드를 실행하는지 알 수 있을까?
커널은 부팅할 때 trap table을 세팅하고, OS는 특정 예외적인 이벤트가 발생했을 때 어떤 코드를 실행할 지를 명시하기 위해 하드웨어에 trap handler들의 위치를 알려 놓는다.
위에서 유저 프로그램이 시스템 콜을 직접 실행하는 것이 아니라고 했다. 시스템 콜에는 시스템 콜 번호가 부여되어 있다.
유저 코드는 시스템 콜 번호를 특정 위치에 저장해두고 시스템 콜 번호로 시스템 콜을 호출한다. 그럼 OS가 trap handler로 시스템 콜 번호에 맞는 시스템 콜을 실행한다.
(이런 간접적인 수행은 protection에 중요하다.
유저 코드가 구체적인 주소를 명시하기보다는 특정한 서비스를 번호를 통해 수행할 수 있고,
공격 프로그램이라고 판단될 시에 하드웨어가 프로그램의 시스템 콜 호출을 막을 수 있다.)
위 6.2를 통해 설명한 것들이 어떻게 활용되는지 확인할 수 있다.
또한 프로세스가 각자 kernel stack을 가지고 있고 kernel stack에 레지스터의 정보를 저장하고 kernel stack에서 복구하는 것을 확인 할 수 있다.
문제점 2 : Switching Between Processes
2. 프로세스를 실행하고 있을 때, 어떻게 현재 실행중인 프로세스를 멈추고 다른 프로세스로 전환(time sharing) 할 수 있을 것인가.
말로만 들었을 땐 해결 방법이 간단해 보인다. OS가 실행중인 프로세스를 멈추고 다른 프로세스를 실행하면 되는 것 아닐까?
하지만 여기엔 잘못된 생각이 있다.
"프로세스가 CPU에서 실행되고 있다"라는 말은 "OS는 현재 실행중이지 않다"는 것을 의미한다.
(OS또한 하나의 프로그램에 불과한 것을 잊으면 안된다.)
그럼 어떻게 OS가 CPU에 대한 제어권을 다시 가져올 수 있을까?
1. A Cooperative Approach : Wait For System Calls
"Cooperative"라는 단어에서 볼 수 있듯이 상당한 협력을 필요로 하는 해결법이다.
OS는 프로세스들을 신뢰하며, 프로세스들이 각자 오래 실행되었다 판단 되면 CPU를 포기하길 기다리는 것이다.
프로세스는 시스템 콜을 호출하면서 OS에게 CPU의 제어권을 다시 넘겨준다.
또는 허락되지 않은 operation이 발생하면 OS로 trap된다.
이 수동적인 방법이 굉장히 이상적이여 보이지만.. 프로세스들이 시스템 콜을 호출하지 않는 다면...?
기계를 재부팅 하지 않고서는 프로세스를 제어할 방법이 없다.
2. A Non-Cooperative Approach : The OS Takes Control
그래서 고안한 방법이 timer interrupt이다.
타이머 장치가 주기적으로 interrupt를 발생하도록 하고, interrupt가 발생했을 때 현재 실행하는 프로세스를 멈추고 미리 명시된 intterupt handler를 OS에서 실행하는 것이다.
앞서 첫번째 문제점, restriced operation의 해결법에서 말했듯, 여기에서도 OS는 interrupt가 발생했을 때 어떤 코드를 실행할 지 하드웨어에 알려야 한다.
그러므로 처음에 부팅할 때, OS는 interrupt handler에 관한 정보를 하드웨어에 알리고, 또 타이머를 세팅한다.
물론 타이머에 관한 것도 privileged operation이다.
결국 timer intterupt로 인해 CPU의 제어권이 OS로 반드시 돌아올 것이라는 확신을 얻을 수 있다.
Saving and Restoring Context
어쨌든 System call 또는 time interrupt 가 발생했을 때, 하드웨어는 현재 실행중인 프로세스에 대한 충분한 정보를 저장해둘 책임이 있다.
process를 switch하기로 결정 되었다면 OS는 context switch라고 하는 low-level 코드를 실행한다.
(어떤 process로 switch할 것인지에 대해서는 OS scheduler에 의해 결정 되지만 뒷 장에 자세히 배우게 될 것이다.)
context switch란?
실행되던 process의 레지스터 값을 pcb에 저장한 후 stack pointer를 다음에 실행할 process의 kernel stack으로 바꾸는 것을 말한다.

6.3 예제를 살펴보자.
process A가 실행되던 중 time interrupt가 발생했다.
그럼 하드웨어는 user mode에서 CPU의 레지스터 상태(프로그램 카운터, 스택 포인터, 플래그 레지스터 등)을 프로세스 A의 kernel stack에 저장하고 user mode에서 kernel mode로 전환한다.
OS에서는 time interrupt handler을 찾아 실행하고, handler에서 OS는 scheduler에 따라 Process B로 context switch하기로 결정한다. 따라서 현재 레지스터 값들을 프로세스A의 process structure(PCB)에 저장하고,
B의 process structure(PCB)에서 process B의 레지스터 값들을 복구한다.
그 후 핸들러가 종료되고 하드웨어는 레지스터의 stack pointer의 위치를 B의 kernel stack으로 변경한다.
마지막으로 kernel mode에서 user mode로 변경한 후 B의 program counter(PC)로 jump한다.
process B는 실행된다.
context switch는 위와 같은 방식으로 현재 실행되던 process의 context를 저장하고 다음 실행될 process의 context를 복구한다.
What is Kernel Stack?
예제에서 k-stack과 proc_t라는 자료구조가 보인다. 이 둘은 무엇이며 kernel stack이 뭔데? 이에 대한 정보가 OS step에서 잘 설명되어 있지 않아 추가적으로 찾아본 정보이다.
Kernel Stack이란?
Process마다 Memory(Ram)에서 kernel stack이 할당된다. kernel stack에는 OS가 kernel mode에서 작업을 수행하기 위해 필요한 정보가 저장된다. 예를 들어 커널 모드에서 호출된 함수, 로컬 변수 등의 정보, CPU의 레지스터 상태, 인터럽트 핸들러 정보 등을 저장한다.
흔히 우리가 알고 있는 user stack과는 전혀 다르다. user stack에서는 user mode에서 실행되는 것들에 대해 저장한다면 kernel stack은 kernel mode에서 수행되는 작업에 대해 저장한다.
위와 같은 정보를 갖고 예제를 다시 살펴 보자. stack overflow를 서치 끝에 자세한 과정을 담은 사진을 찾을 수 있었다.
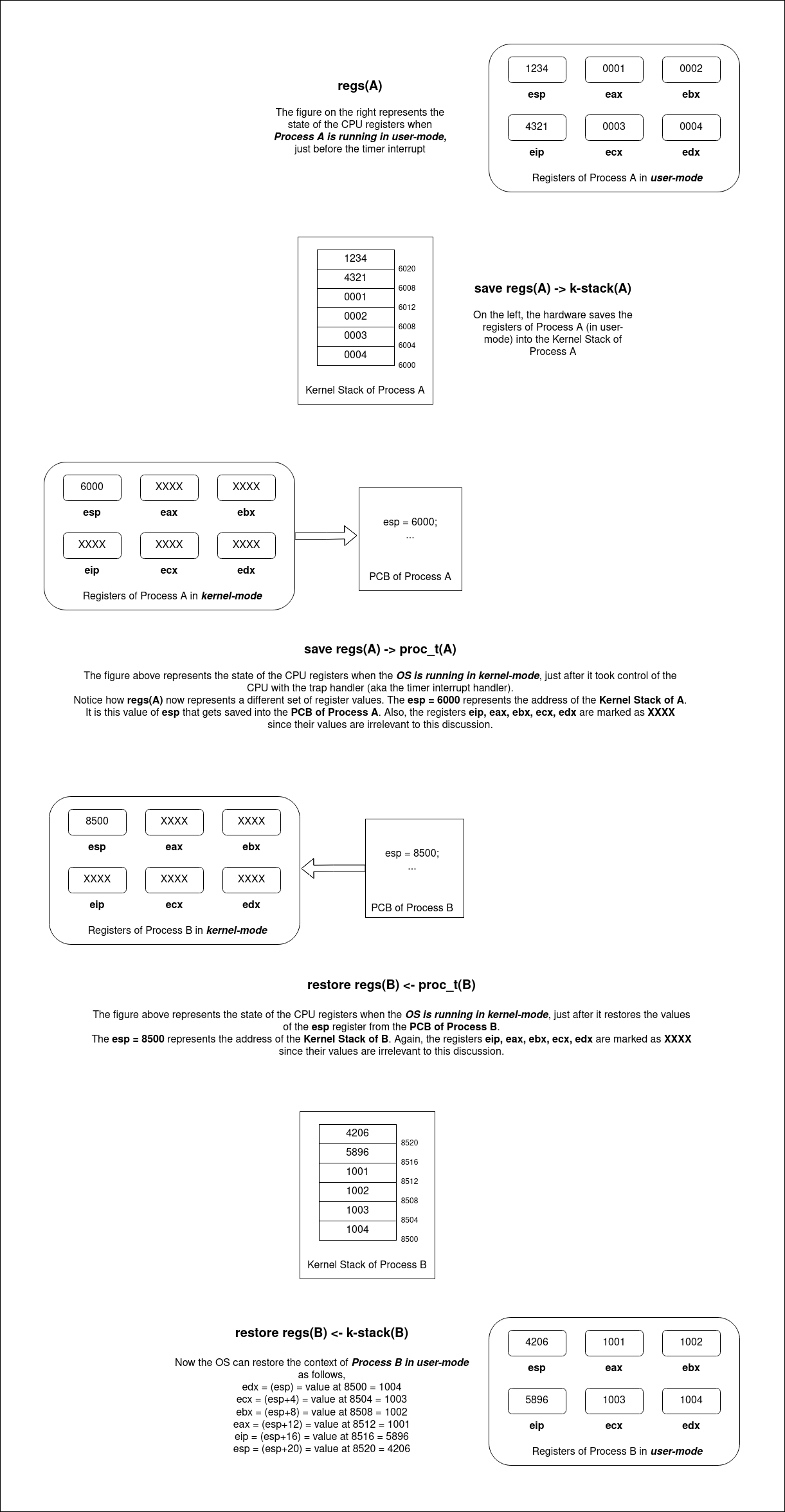
user mode에서 kenel mode로 전환되기 전, 하드웨어는 CPU register에 저장되어 있는 프로세스A에 대한 값들을 kernel stack에 저장한다. 그리고 kernel mode로 전환하여 context switch가 되기로 결정이 되면 kernel stack의 주소를 PCB에 저장한다.
다음에 실행되기로 한 프로세스의 PCB에서 kernel stack의 주소를 복구한다. (레지스터 포인터를 B의 kernel stack 주소로 옮긴다.) 그리고 kernel stack에 저장되어 있는 레지스터 값들을 CPU 레지스터에 복구한다.
user mode로 전환한 뒤 프로세스 B를 실행한다.
이제 kernel stack을 통해 context switch가 발생했을 때 CPU 상태를 빠르게 저장하고 복구하는 과정을 이해할 수 있을것이다.
Concurrency에 대한 걱정
이쯤에서 누군가는 의문을 가질지도 모른다. "프로세스가 시스템 콜을 호출할 동안 time interrupt가 발생하면 어떻게 될까?", "interrupt handler동안 또 다른 interrupt가 발생하면 어떡할까?"
OS는 interrupt를 처리하는 동안 다른 interrupt가 CPU에 전달되지 못하도록 한다. 물론 너무 오랫동안 interrupt를 막았다가는 interrupt가 소실될 가능성이 있다.
또 데이터에 대해 동시 접근을 막기 위해 lock구조도 있다. 아마 자세한건 뒷장에서 볼 수 있을 것이다.
'운영체제 > Operating Systems in Three Easy Pieces' 카테고리의 다른 글
| 6. Virtualization) Multi-level Feedback (0) | 2023.07.06 |
|---|---|
| 5. Virtualization) CPU Scheduling (0) | 2023.07.05 |
| 3. Virtualization) Processes API (0) | 2023.06.26 |
| 2. Virtualization) Processes (0) | 2023.06.21 |
| 1. Virtualization) dialogue (0) | 2023.06.19 |