
이번 챕터에서는 멀티프로세서 스케줄링에 대해 알아볼 것이다.
예전이야 cpu가 하나만 있었지만 현재 multiprocessor은 데스크탑, 랩탑, 모바일 등 매우 흔한것이 되었다.
mulicore processor의 대중화는 좋은 현상이지만 이로 인해 몇가지 문제가 발생했다.
그중 하나는 과거에 개발된 전형적인 애플리케이션들은 하나의 cpu만 사용하기 때문에 cpu가 추가되었다고 해서 빨라지지 않는다는 것이다. 따라서 우리가 코드를 병렬적으로 rewrite할 필요가 있다.
다른 문제점으로는 OS가 multiprocessor scheduling을 해야한다는 점이다.
이런 문제점들을 이해하기 위해서는 우선 Multiprocessor의 아키텍처에 대해 이해해야될 것이다.
Background : Multiprocessor Architecture
single-CPU 하드웨어와 multi-CPU하드웨어에는 근본적으로 어떤 차이점이 있을까?
가장 큰 차이점은 하드웨어의 cache 사용에 있다.(여기서는 대략적으로만 다루겠지만 나중 챕터에서 자세히 다루게 될 것이다.)

단일 CPU에는 Cache계층이 존재한다. 메인메모리는 모든 데이터를 갖고 있지만 데이터에 접근하는게 매우 느린 반면,
cache는 작고 빠른 대신 메인메모리에서 중요한 데이터 일부만 갖고 있다.
이렇게 자주 쓰는 데이터들을 캐시에 저장해 놓음으로써, 크고 느린 메모리를 빠른것처럼 보이게 한다.
예를 들면, single-CPU시스템에서 어떤 프로그램이 메인메모리에 있는 데이터를 불러올 필요가 있을 때, 처음에는 오랜 시간이 걸려 데이터를 load할 것이다. 하지만 프로세서가 이 데이터가 재사용될것이라고 예측하고 CPU의 cache에 데이터의 복사본을 저장해 놓는다면 후에 프로그램이 같은 데이터를 다시 필요로 할때 CPU는 cache를 먼저 체크하여 데이터를 빠르게 찾을 수 있을것이다.
이 예를 보면 알 수 있듯이 캐시는 Locality라는 개념을 기본으로 한다.
1. temporal locality
데이터를 접근할때, 같은 데이터를 나중에도 다시 접근할 것이라는 개념이다.
2. spatial locality
x에 위치해 있는 데이터를 접근할 때, 나중에도 위치 x의 주변에 접근할 가능성이 높다는 개념이다.
(배열을 접근할때 spatial locality가 얼마나 효율적일지 생각해보자.)
이런 locality를 통해 시스템은 어떤 데이터를 cache에 저장할지 효율적인 추측을 할 수 있다.
이를 Multiple processor에 적용하면 문제점이 있다.
Problem : Cache coherence 캐시 일관성
프로그램 A가 CPU1에서 실행되고 있고, 프로그램이 데이터 d를 필요로 할때, CPU1이 메인메모리에 있는 address A에서 데이터 d를 읽어와 Cache1에 저장했다고 가정해보자. 프로그램이 address A의 데이터를 수정할 때, 메인메모리의 address A에 접근하는 대신 Cache1에 있는 데이터 d를 대신 수정할 것이다(d→d'). 그 후 OS가 CPU1에서 실행되고 있는 프로그램 A를 중지하고 CPU2에서 실행하기로 결정 한다면 Cache2에 데이터 d가 없기 때문에 CPU2는 메인메모리에서 데이터 d를 다시 읽어와야 할 것이다.
이 때 우리는 수정된 데이터 d'를 읽어오는게 아니라 과거의 데이터 d를 읽어오게 되고 이런 문제를 cache coherence라고 한다.
Bus snooping
이에 대한 가장 기본적인 해결법이 bus snooping이다. 각 cache가 메인메모리를 연결하는 bus를 관찰하고, 캐시에 있는 데이터에 있는 데이터가 수정됐을때 CPU가 유효하지 않은 복사본들에게 이를 알리고 업데이트 or 삭제하는 것이다.
하지만 이 방법이 완벽한게 아닌게 수정된 data를 bus로 전달해 메인메모리에 다시 작성하는 것은 아주 나중일 것이기 때문이다.
Problem : Synchronization
또 다른 문제로는 동기화 문제가 있다. (후에 다른 챕터에서 더 자세히 알아볼것이고 여기서는 대략적인 스케치정도만 한다.)
바로 동시에 shared data를 접근하는 것이다. 동기화에 관한 문제는 lock을 활용하면 해결이 되지만 이에 관해서는 performance문제가 있다. CPU가 많아지고 shared data에 접근하려는 프로세스가 많아진다면 데이터 구조에 접근하는데 있어서 점점 느려질것이다.
Final Issue : Cache Affinity 캐시 선호도
마지막 문제는 cache affinity이다. cache affinity는 multiprocessor의 cache scheduler을 설계하는데서 발생한다.
위의 예제에서 보았듯, CPU1에서 실행했던 프로세스 A를 후에 CPU2에서 실행해야 한다면 기존에 저장해 놓았던 cache, TLB등을 다시 메인메모리에서 reload해야한다. 결국 성능에 문제가 생기게 된다!
따라서 multiprocessor 스케줄러는 cache affinity를 고려하여 스케줄링을 결정해야한다.
같은 CPU에서 프로그램이 실행될 수 있도록 선호해야한다!
기초적인 것들을 대략적으로 알았으니 이제 multi processor의 스케줄링에 대해 알아보자.
Single-Queue Scheduling
실행해야 할 모든 job들을 single queue에 두고 스케줄링 하는 것을 single-queue multiprocessor scheduling 즉, SQMS라고 한다. SQMS의 장점은 간단하다! 왜? 단일 큐에서 job을 꺼내다 쓰면 되니까!
하지만 이는 명백한 결점을 가지고 있다.
1. lack of scalability
job을 저장하는 single queue는 여러 CPU가 접근하기 때문에 shared data이다. 따라서 synchronization을 위해 lock을 해야 할 것이다. 하지만 Lock이 synchronization을 보장할지라도 performance를 상당히 저하시킨다.
특히 CPU가 많으면 많을수록 lock 오버헤드는 점점 커질것이다.
2. cache affinity
두번째 문제는 cache affinity문제이다. job A, B, C, D, E가 있고 single queue에 저장되어 있다고 하자.
CPU가 4개가 있을때 각 time slice마다 큐에서 다음 Job을 정할 것이다. 하지만 단일 큐에서 job을 고르기 때문에 각 job들은 매번 다른 CPU에서 작동할 확률이 높다. 그리고 이건 위에서 설명했듯 cache affinity에 최악이다.
이런 문제를 SQMS는 다른 방법을 통해 해결한다.
CPU가 같은 Job을 계속 실행하되 job E를 계속 이주 시키며 실행하는 것이다. 이를 통해 affinity fairness를 성취할 수 있다.
하지만 어쨌던간에 SQMS는 단순함의 장점이 있지만 명백한 단점이 존재한다 : synchronization 오버헤드 때문에 scalable하지 않다.
Multi-Queue Scheduling
이제는 각 CPU마다 queue가 할당 된다. 이를 multi-queue multiprocessor scheduling 즉 MQMS라고 한다.
그리고 각 CPU에 할당된 queue에는 서로 다른 스케줄링 방식이 채택될 수 있다.
한마디로 독립적이다! 예를 들어 CPU1은 round robin CPU2는 MLFQ를 통해 다음 job을 스케줄링 할 수 있다.
CPU마다 서로다른 queue가 할당되기 때문에 synchronization문제를 해결할 수 있다.
CPU가 증가할수록 queue도 증가하므로 MQMS는 scalable하다.
그리고 cache affinity를 제공한다.
위의 예제를 보자. CPU0에는 Q0이 CPU1에는 Q1이 할당 되어 있다.
그리고 각 CPU는 각각의 queue에 접근하여 다음 job을 결정한다.
이때 각 큐에 있는 job을 실행하기 때문에 같은 CPU에서 job을 실행하고 cache affinity를 만족시킨다.
Problem : Load imbalance
하지만 MQMS 또한 load imbalance라는 문제점을 가지고 있다.
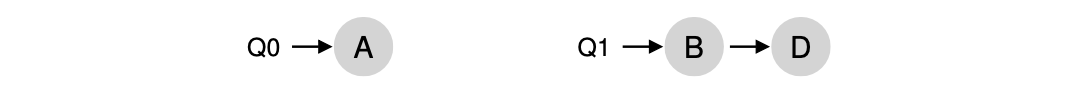

위의 상황을 가정했을때 Q0에는 job A만 존재하고 따라서 CPU0을 A가 독점하게 된다.
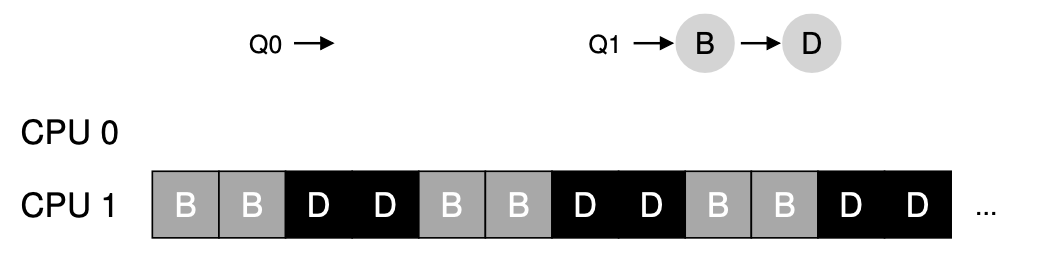
그렇다면 A가 먼저 실행되어 종료될것이고 CPU0은 idle한 상태가 된다..!
Solution : Migration
이에 대한 해결법은 job을 이동시키는 것이다.
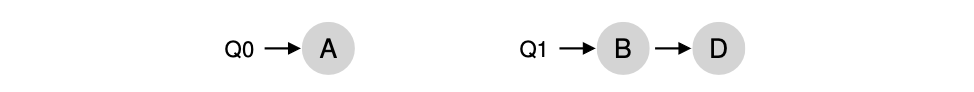

Q0에는 job A만 있고 Q1에는 job B,D가 있다. 아주 imbalance한 상태이다.
따라서 CPU0은 CPU1과 job을 switch할 수 있다.
또는 swith방법 대신 work stealing 방식이 있다. 즉, 적은 job을 갖고 있는 queue가 많은 job을 갖고 있는 queue의 job을 말그대로 훔치는 것이다.
Linux Multiprocessor Schedulers
그럼 리눅스는 어떤 스케줄러를 채택했을까? 안타깝게도 공통된 해결책은 없고 세가지 스케줄러를 사용한다.
: O(1)스케줄러, 완전 공정 스케줄러(CFS), BF스케줄러(BFS)
O(1)과 CFS는 multi queue를 사용하고 BF스케줄러는 single queue를 사용한다.
O(1)스케줄러는 우선 순위 기반 스케줄러이며 MLFQ와 상당히 유사하다. 시간이 지나면 프로세스의 우선순위를 변경하고 최우선 순위를 가진 프로세스를 스케줄링한다.
CFS는 결정론적 비례 공유 접근 방식이다. 이전에 설명한 Stride 스케줄링과 유사하다.
BF스케줄러 또한 비례 공유 방식이다.
'운영체제 > Operating Systems in Three Easy Pieces' 카테고리의 다른 글
| 10. Virtualization) Address Translation (3) | 2024.09.08 |
|---|---|
| 9. Virtualization) Address Spaces (0) | 2024.04.07 |
| 7. Virtualization) Lottery Scheduling (0) | 2024.03.12 |
| 6. Virtualization) Multi-level Feedback (0) | 2023.07.06 |
| 5. Virtualization) CPU Scheduling (0) | 2023.07.05 |