
이 챕터에서는 fair-share 스케줄러라고도 부르는 proportional-share 스케줄러에 대해서 알아 볼거다.
이전의 Multiple-level Feed-back Queue(MLFQ)에서는 Completion time과 Response time의 최적화에 중점을 뒀다면,
Proportion-share 스케줄러는 각 job들이 특정한 비율의 cpu 시간을 보장받을 수 있도록 하는 스케줄러이다.
lottery scheduling이 proportion-share스케줄러로 잘 알려져 있다.
Ticket : Represent Your Share
lottery scheduling에는 ticket이라는 개념이 있다.
ticket이란? 프로세스가 사용해야하는 자원의 몫을 나타낸다. 즉 티켓의 비율은 시스템 자원의 몫을 나타낸다.
예를들어, 프로세스 A가 75개의 티켓이 있고 B가 25개의 티켓을 가지고 있다면 A는 75%의 cpu 타임을 받아야 할 것이고 B는 25%의 cpu 타임을 할당받아야 할 것이다.
lottery scheduling의 원리는 아주 단순하다. 스케줄러는 티켓의 총 개수만 알면 된다.
그런 다음 스케줄러는 0에서 99까지의 숫자중 랜덤하게 한 숫자를 뽑는다.
이를 winning ticket이라고 하고 이 숫자가 0~74의 숫자면 A가 75~99의 숫자면 B 프로세스가 실행된다.

lottery scheduling은 이런 무작위성 추첨을 통해, 원하는 cpu타임을 할당받을 확률적인 정확성을 제공하지만 정확히 그 비중을 할당받는 것을 보장하지는 않는다. 위의 예에서도 20번의 실행동안 B는 4번, 즉 20%에 그쳤다.
하지만 더 오랫동안 A와 B가 cpu time을 경쟁한다면 목표한 퍼센트에 근접할 수 있을것이다. (이는 뒤의 그래프에서도 추가적으로 설명한다.)
Implementation
Ticket Mechanisms
Lottery scheduling은 티켓을 조작하는 메커니즘도 제공한다.
1. ticket currency
예를 들어 유저 A와 B가 각자 100개의 티켓이 주어졌을때, A의 통화에서 A가 a1, a2의 2개의 job에 각각 500개의 티켓을 부여하고, B의 통화에서 B가 한개의 job b에 10개의 티켓을 부여한다면, 시스템은 global한 통화를 적용하여 a1, a2, b에 각각 50, 50, 100개의 티켓으로 전환한다.
2. ticket transfer
단순하게 일시적으로 티켓을 다른 프로세스에게 넘기는 것이다.
3. ticket inflation
프로세스가 일시적으로 자신의 티켓 개수를 늘리거나 줄일 수 있다. 하지만 이런 inflation은 각 프로세스가 서로를 신뢰하지 않고는 큰 문제가 발생할 수 있다. 예를 들어 한 프로세스가 티켓 수를 늘려 cpu를 점령할 수 있다. 따라서 서로 신뢰할 수 있는 환경에서 cpu시간이 좀 더 필요한 상황에 유용하게 사용될 수 있다.
Fairness 계산
이제 lottery scheduling의 효율을 계산해 볼 필요가 있다.
따라서 두개의 job의 completion time을 비교할 수 있는 fairness metric을 살펴볼거다.
예를 들어, R=10 즉 첫번째 job이 time 10에 완료되고 두번째 job이 20에 완료되었을때, F = 10/20 = 0.5이다.
두 job이 거의 비슷한 시간에 완료되면 F는 1에 점점 수렴하고 이를 fair하다고 한다.
이전에 설명 했듯이 9.2를 보면 job의 경쟁 시간이 길 수록 fairness가 1로 수렴한다. 즉, 원하고자 했던 cpu time을 할당받을 수 있다.
How To Assign Tickets?
lottery scheduling에는 아직 한가지 문제가 남아있다. job에 어떻게 티켓을 배분할 것인가?
한가지 방법은 사용자가 제일 잘 알것이라 생각하고 맡기는거지만 이는 정확한 솔루션은 될 수 없고,, ticket-assignment 문제는 여전히 남아있는 문제이다.
Use Randomness
lottery scheduling의 장점은 그래서 뭘까??? 바로 Ran-domness이다.
random 접근법은 전통적인 스케줄링 방법에 비해 3가지 이점은 확실히 갖는다.
1. 랜덤 접근법은 전통적인 알고리즘이 겪는 이상한 극단적인 케이스들을 피할 수 있다.
예를들어, LRU는 일부 순환 순차적 워크로드에서 최악의 경우 최악의 성능을 달성하지만 무작위성은 이런 최악의 경우가 없다.
2. 무작위성은 가볍다.
전통적인 스케줄링은 각 프로세스가 할당받는 cpu타임을 추적해야하지만 랜덤 접근법은 각각이 가지고 있는 티켓의 개수 등 최소한의 상태만 필요하다.
3. 무작위성은 빠르다.
무작위적인 숫자를 생성하는 것이 빠르면 결정도 빠를 것이다.
따라서 속도가 필요한 곳에서는 무작위성을 활용할 수 있다.
Stride Scheduling
위에서 lottery scheduling에 대해 알아봤다. 하지만 lottery scheduling에서 job의 길이가 짧을 때 proportional한 비율을 배정받지 못한다는 것을 배웠다.
이런 이유로 고안된 것이 stride scheduling이다.
stride scheduling 또한 단순하다. 각 job들은 ticket의 비율에 반비례하여 stride를 갖는다.
예를 들어 A,B,C가 100, 50, 250개의 티켓을 각각 갖고 있다면 큰 숫자, 여기서는 10,000을 나눠, A,B,C가 각각 100, 200, 40의 stride값을 가진다. 그리고 프로세스가 실행될때마다 이 stride값을 더하여 가장 작은 pass를 가진 job을 다음 프로세스를 결정한다.
9.3을 보면 A는 2번, B는 1번, C는 5번이 실행됬고 이는 티켓 비율과 딱 맞아떨어진다.
결국 stride scheduling은 각 주기의 끝에서 정확한 비율의 할당량을 얻는다.
이렇게 본다면 stride scheduling이 lottery scheduling보다 좋아보인다.
하지만 왜 lottery scheduling을 사용할까?
만약 stride schduling에서 중간에 새로운 job이 들어올때 해당 Job의 pass값을 어떻게 정해야 할지 문제가 생긴다. 0으로 한다면 cpu를 독점할 것이다. 반면 lottery scheduling에서는 중간에 job이 추가되어도 ticket 개수만 추가하면 된다.
The Linux Completely Fair Scheduler(CFS)
현재 리눅스는 다른 방식의 더 보완된 fair-share scheduling을 사용한다.
Completly Fair Scheduler(CFS)라고 하며 fair-share scheduling이지만, 더 효율적이고 확장 가능한 방식이다.
대부분의 스케줄러의 time slice 시간은 고정되어 있는 반면에, CFS의 time slice 시간은 다르다.
CFS의 목적은 간단하다. 모든 프로세스들이 공정하게 CPU를 나눠갖는것.
→ virtual runtime(vruntime)라고 알려진 counting-based technique에 의해 가능하다.
각 프로세스가 실행될 때 vruntime이 축적되고, 스케줄러는 가장 작은 vruntime 프로세스를 다음 프로세스로 결정한다.
이때, CFS가 switch를 자주 하면 fairness가 증가하겠지만 context switch에 대한 cost가 커져 perfomance가 떨어질 것이고,
너무 적게 switch를 한다면 fairness가 떨어질 것이다.
→ sched_latency도입
sched_latency는 switch가 발생하기 전 프로세스가 얼마나 실행되야 할지 결정한다. 전형적으로 sched_latency는 48ms이고,
process의 개수로 나눠 각 프로세스는 48/n ms만큼 time slice당 실행된다. (프로세스의 개수가 너무 많아 time slice가 자주 발생할 것에 대비해 CFS는 min_granularity를 6ms로 지정하고 time slice의 시간을 min_granularity만큼은 보장한다.)
예를 들어, 프로세스가 10라면 sched_latency를 10으로 나눠 time slice는 4.8ms가 되야 할 것이다. 하지만 min_granularity로 인해 time slice의 주기는 6ms가 될 것이다.
CFS는 주기적으로 발생하는 timer interrupt를 이용한다. 고정되어 있는 timer interrupt때 결정을 내릴 수 있다.
즉 CFS는 time interrupt가 발생했을 때 현재 job이 실행을 마쳤는지에 대한 여부를 판단한다. 그렇다고 time slice의 값이 꼭 timer interrupt interval의 배수가 될 필요는 없다.
Weighting
CFS는 티켓이 아닌, 유닉스 메카니즘으로 알려져 있는 프로세스의 nice level을 통해 프로세스의 priority를 관리한다.
각 프로세스는 -20~+19사이의 nice값을 배정받고(default of 0), 양수는 낮은 priority, 음수는 높은 priority를 의미한다.
또한 CFS map은 nice value에 따른 weight값이 배정되어 있다.

이 weight 값으로 각 포로세스의 효율적인 time slice 시간을 계산할 수 있다.
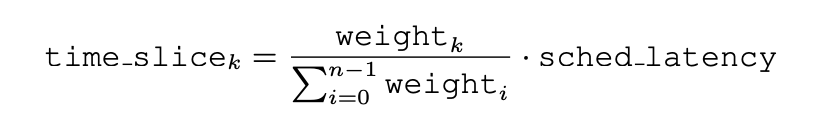
예를들어, A와 B 2개의 job이 있고, A에게는 높은 priority인 nice값이 -5, B는 디폴트 값인 0이 부여된다면,
A의 weight는 3121이고 B의 weight는 1024이다. 따라서 A와 B의 time slice를 계산한다면 A는 대략 3/4 * sched_latency, B는 대략 1/4 * sched_latency가 될것이다.
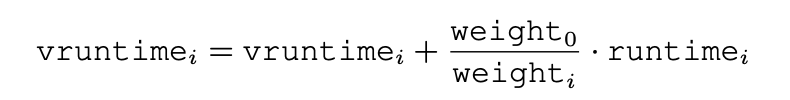
vruntime도 다음과 같은 새 공식이 적용된다.
Using Red-Black Tree
위에서 말했듯 CFS의 가장 중요하게 생각하는건 효율성이다. 효율성을 결정하는 많은 요소 중 하나를 꼽자면
스케줄러가 다음에 실행할 프로세스를 찾을 때, 이 과정이 빨라야 한다는 것이다.
현대 시스템들은 대략 1000개 이상의 프로세스가 있기 때문에 list구조로 탐색하기엔 많은 시간이 걸린다.
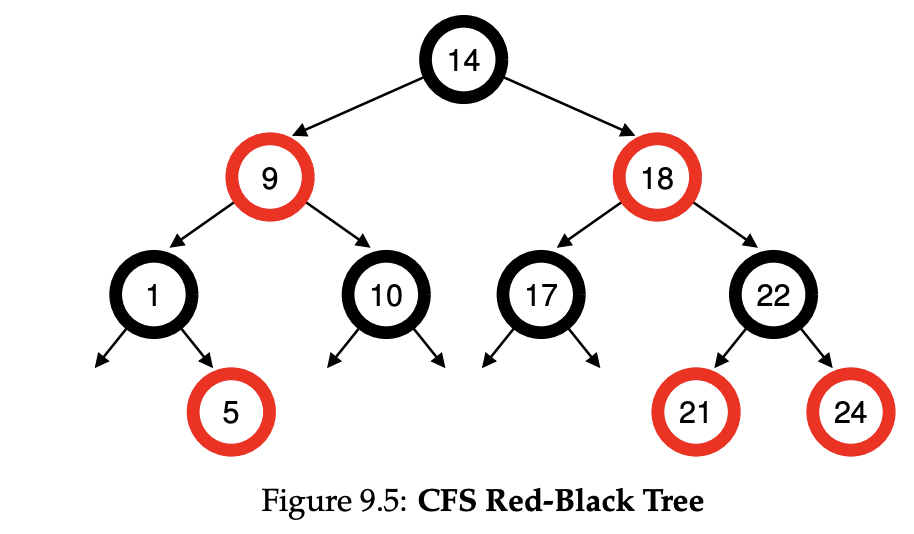
따라서 CFS가 이를 해결하기 위해 프로세스를 red-black tree로 관리한다.
모든 프로세스를 red-black tree로 관리하진 않고, running or runnable 프로세스만 red-black tree로 관리하고 I/O작업으로 인해 blck된 프로세스는 red-black tree에서 제거된 뒤 다른 곳에서 관리된다.
Dealing With I/O And Sleeping Processes
CFS는 다음에 실행될 프로세스로 가장 적은 vruntime을 가진 프로세스를 선택하는데 이에 대한 문제점이 있다.
바로 어떤 job이 오랜 시간 sleep한 후 다시 실행하게 된다면 오랜 시간 cpu를 점령할 것이기 때문이다.
그래서 CFS는 최소 vruntime을 설정하고 이 방식으로 starvation을 해결한다.
'운영체제 > Operating Systems in Three Easy Pieces' 카테고리의 다른 글
| 9. Virtualization) Address Spaces (0) | 2024.04.07 |
|---|---|
| 8. Virtualization) Multi-CPU Scheduling (1) | 2024.03.19 |
| 6. Virtualization) Multi-level Feedback (0) | 2023.07.06 |
| 5. Virtualization) CPU Scheduling (0) | 2023.07.05 |
| 4. Virtualization) Direct Execution (0) | 2023.06.29 |